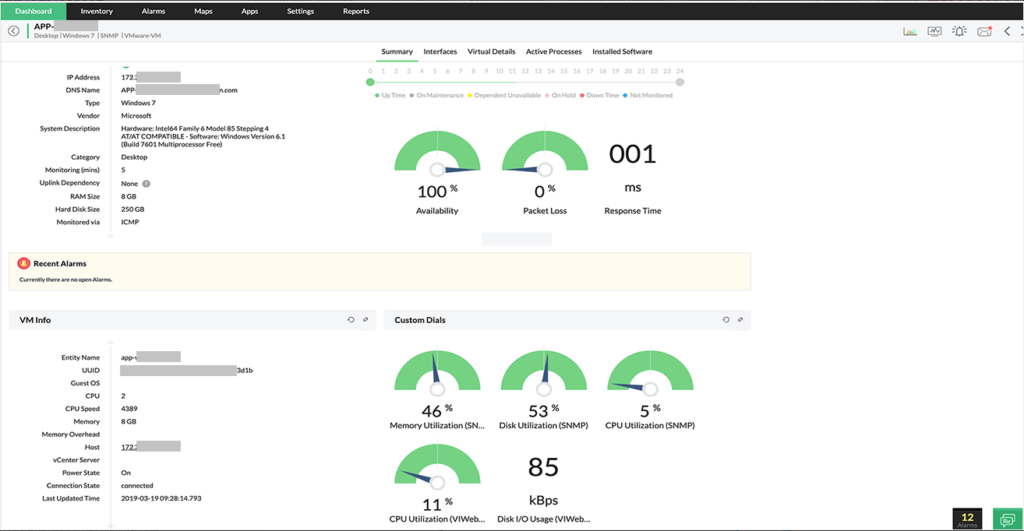
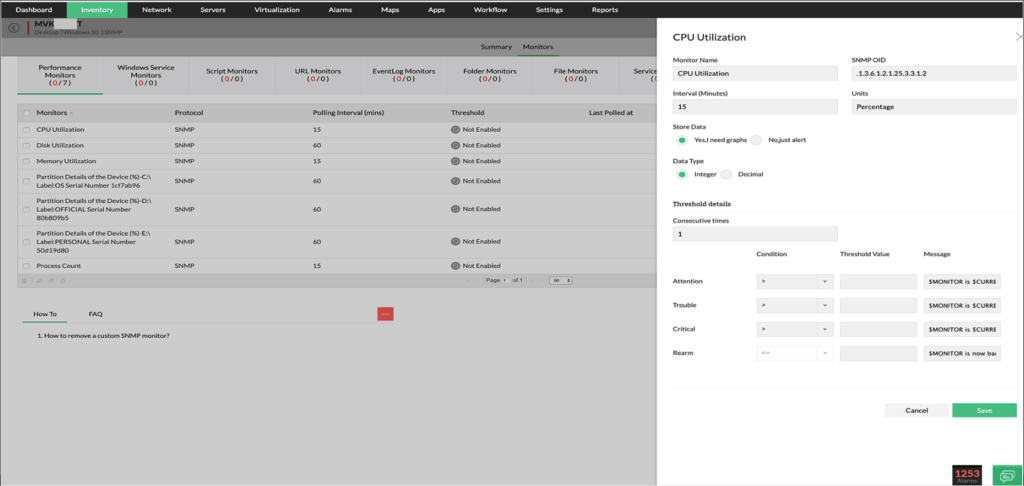
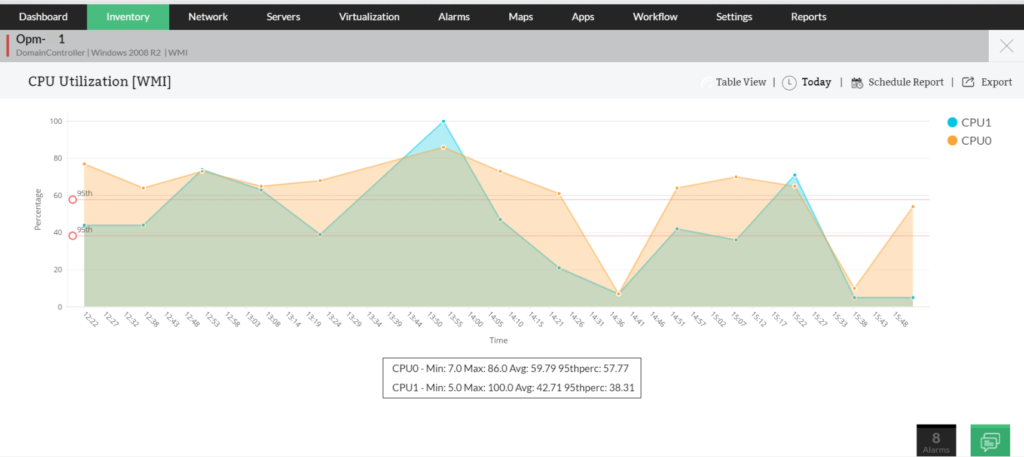
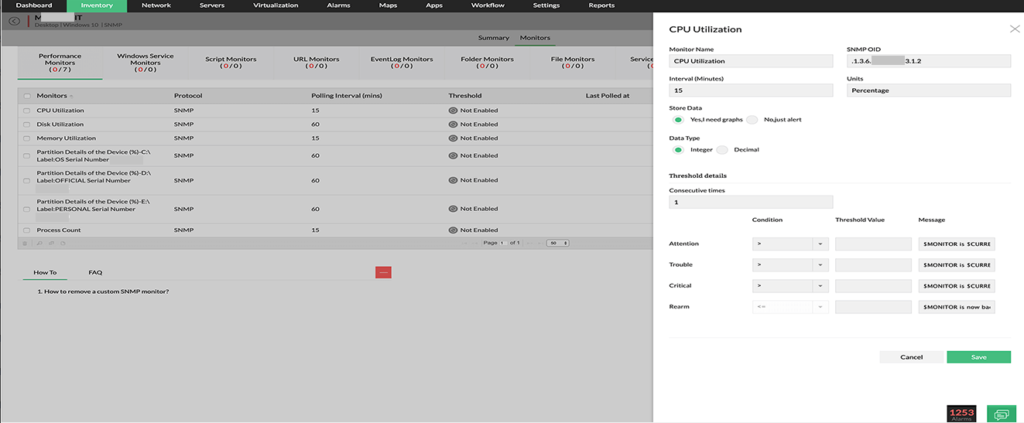
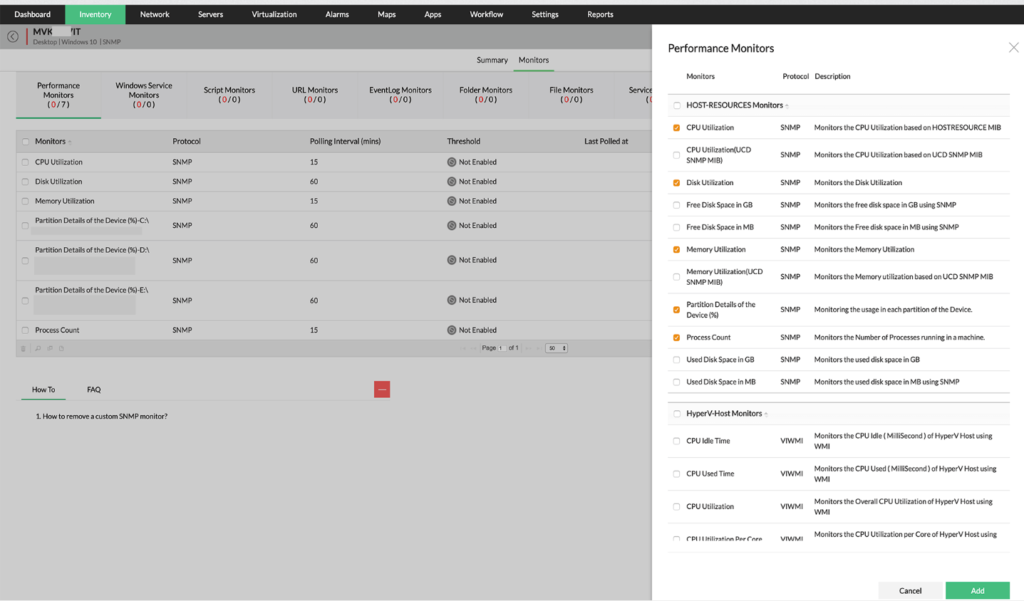
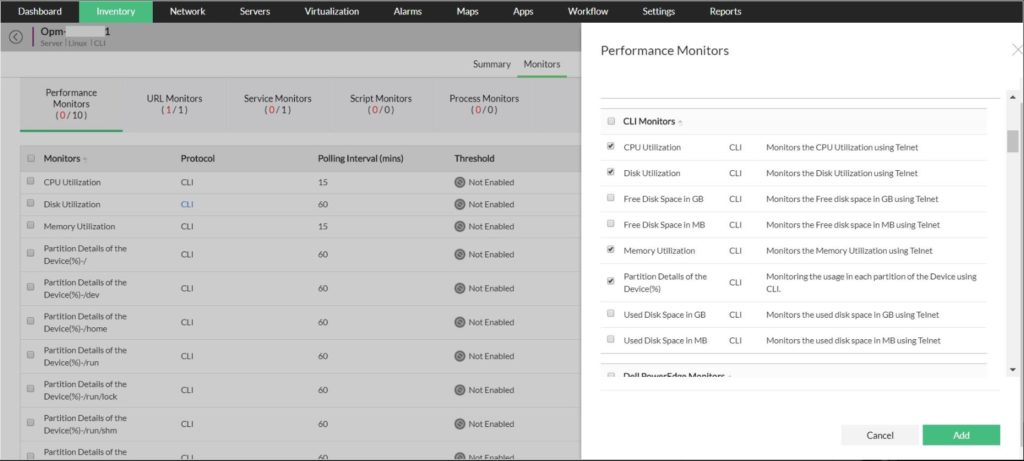
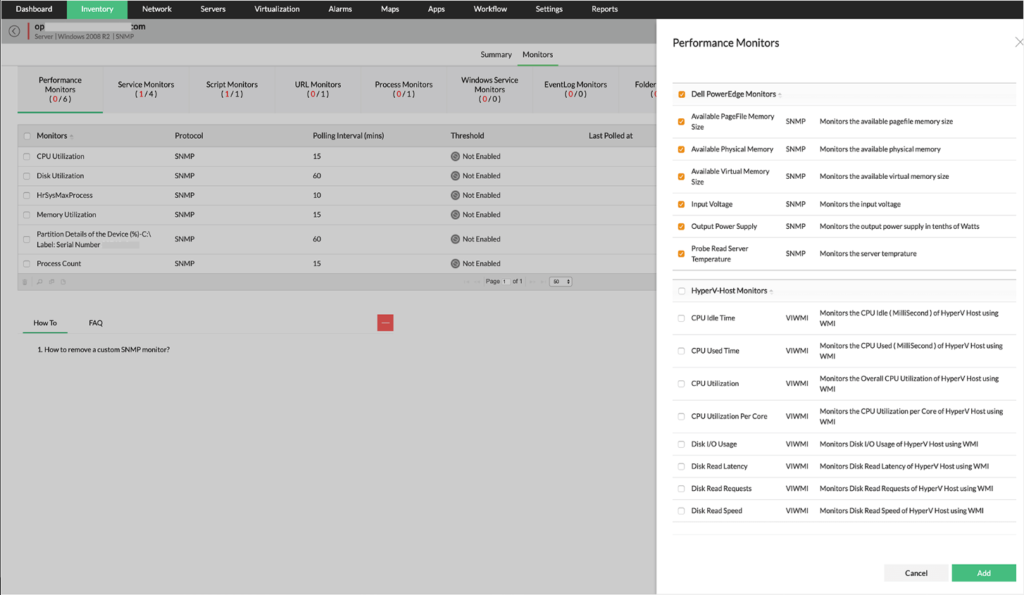
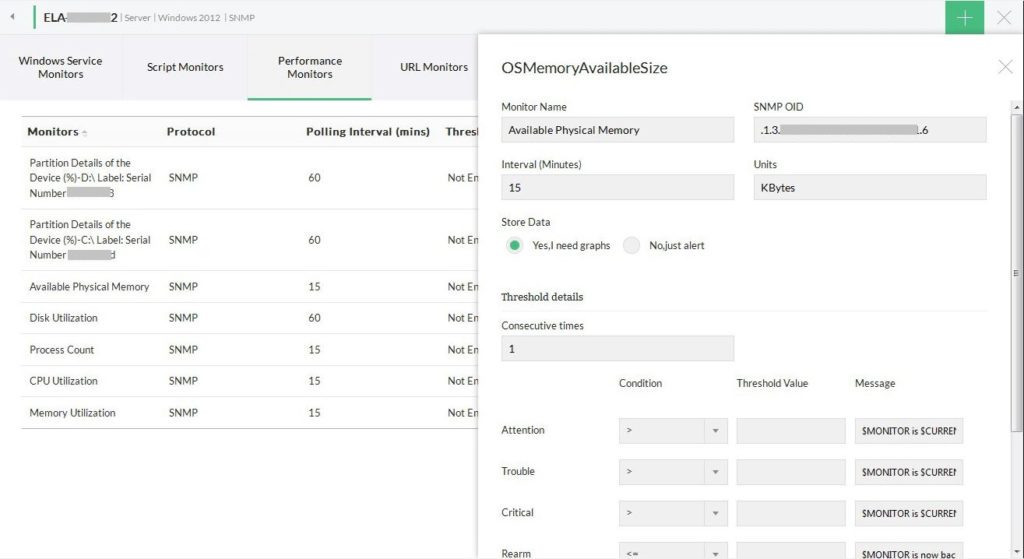
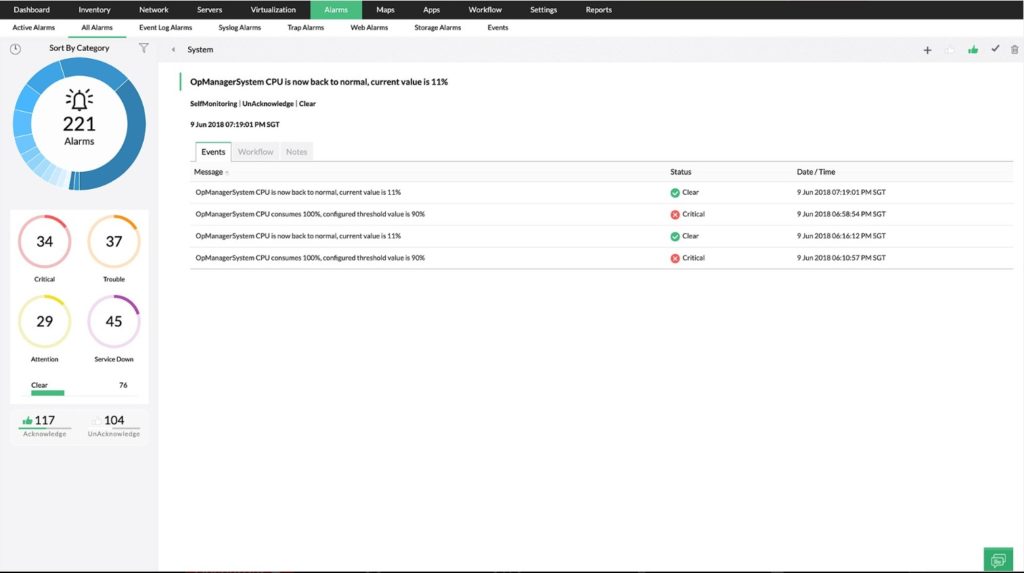
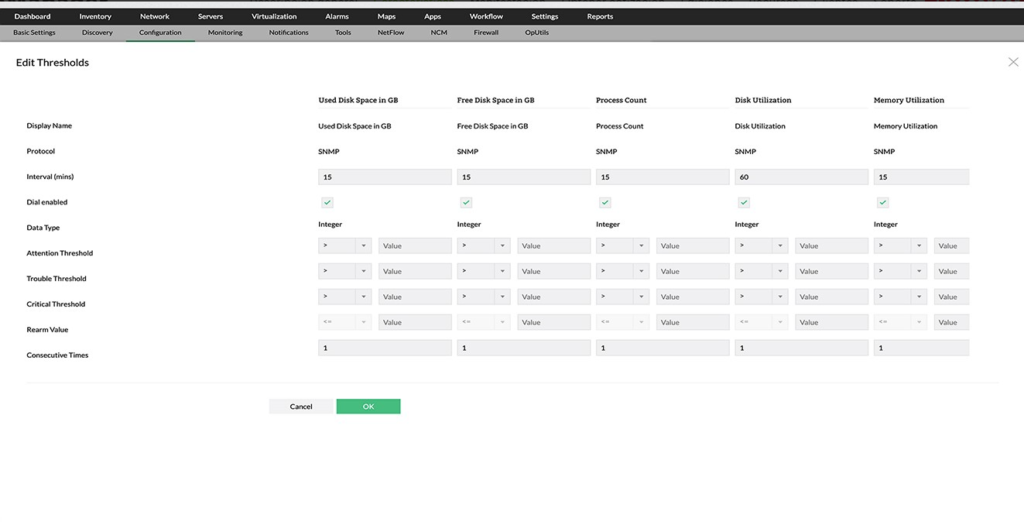
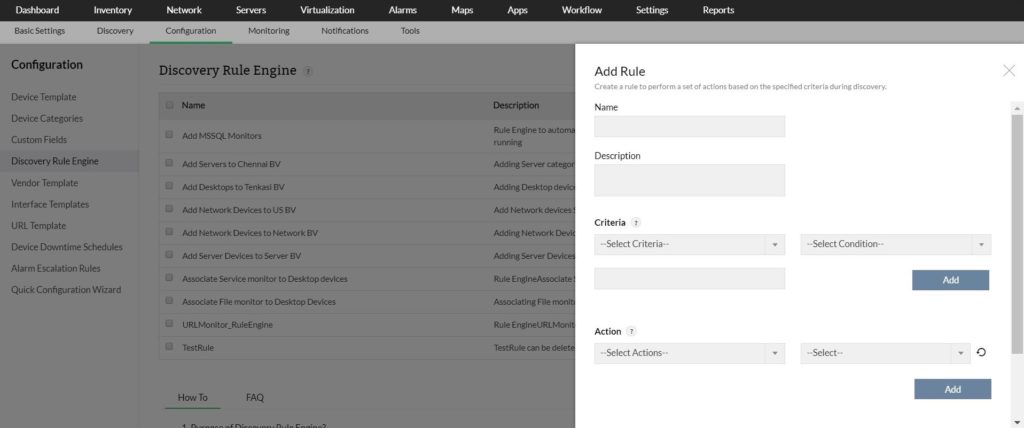
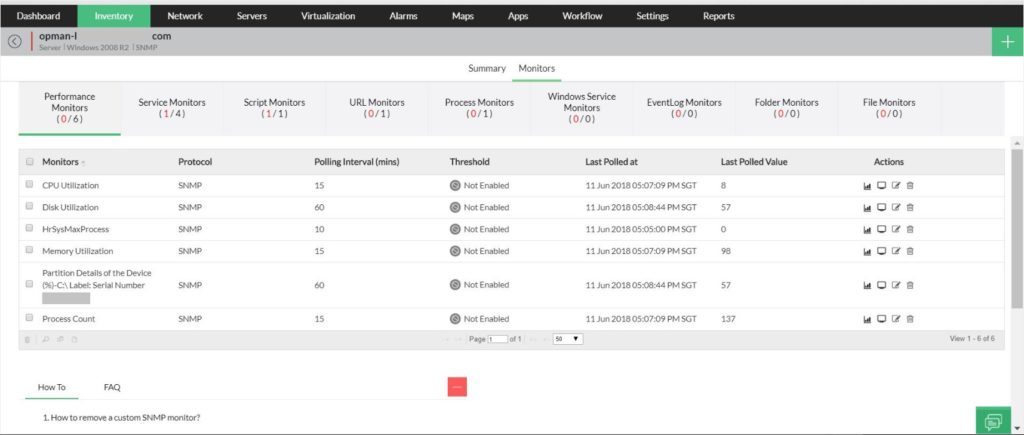
Monitoreo de disco
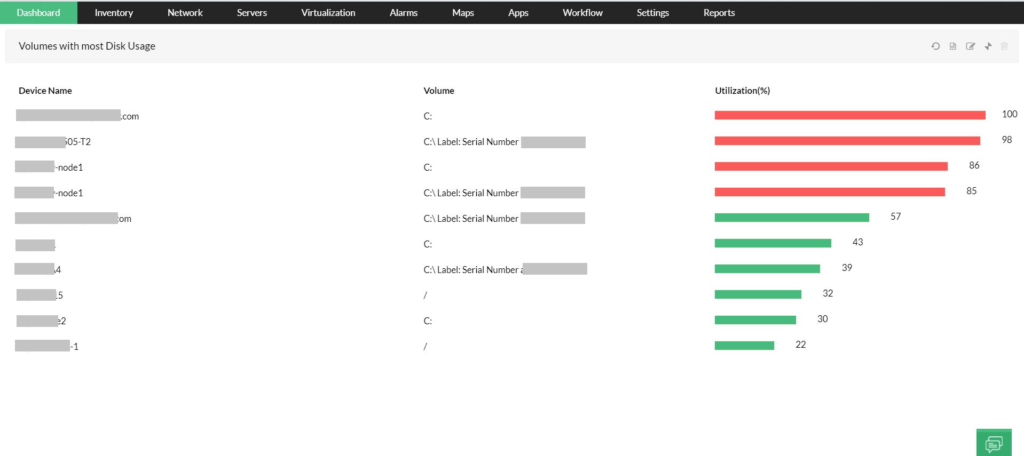
-Utilización del disco
-Lecturas de disco
-Escrituras en disco
-Recuento de disco sin espacio
-Monitores de particiones de disco
-Longitud de la cola de disco
-Espacio libre en disco en GB
-MB de iones de espacio libre en disco
-Espacio en disco usado en GB
-Espacio en disco usado en MB